Tech Community で投稿されていた Azure Redis Timeouts - Server Side Issues が Azure Redis を使う際に注意すべきポイントなどをよくまとめてくれているなと思ったのでの日本語翻訳してみた。
概要
クライアント、ネットワーク、サーバーサイドの要因など、Redis クライアント側でタイムアウトが発生する理由は多数あります。 また、使用するクライアントライブラリによってエラーメッセージが異なる場合もあります。 クライアントアプリケーションが Redis サーバー側からの応答をタイムリーに受信できない場合、Azure Cache for Redis のタイムアウトがクライアント側で発生します。タイムアウト値が期限切れになるより前に、クライアントアプリケーションがレスポンスを受信しなかった場合は、いかなる場合もタイムアウトが発生し、Redisタイムアウトエラーメッセージとしてクライアントアプリケーションログに記録されます。Azure Cache for Redis もしくは、それをホストしている VM 上でなんらかの問題があった場合、クライアント側でもRedisタイムアウトが発生する可能性があります。もし遅延の原因がサーバー側にあった場合、クライアントアプリケーションは Redis サーバーからの応答をタイムリーに受信することができず、タイムアウトが発生する可能性があります。
一般的な問題を列挙します。以下は、一般的なサーバーサイドの要因によりタイムアウトが発生する要因です。
- サーバーサイドのアップデート/パッチ
- 実行時間の長いコマンド
- サーバーのCPU高負荷
- サーバーのメモリ高負荷
- Redis サーバーの帯域幅制限の超過
クライアント、またはネットワーク起因の Redis タイムアウトの原因については、次の TechCommunity の記事を参照してください 。
Azure Redis Timeouts - Client Side Issues
Azure Redis Timeouts - Network Issues
1. サーバーサイドのアップデート/パッチ
Redis サーバーで更新が発生すると、クライアント側でRedisタイムアウトが発生する場合があります。これは想定されたものであり以下に説明する設計になっています。
Azure Cache for Redis の Standard/Premium Tier は、2つの Redis ノードから構成されています。各ノードは単一の Redis サーバープロセスを実行し、専用の VM を持っています。
1つのインスタンスは「プライマリ」ノードで、もう1つは「レプリカ」ノードです。プライマリノードは、データをレプリカノードに継続的に複製します。
プライマリノードが予期せずダウンした場合、レプリカは通常10〜15秒以内にプライマリに昇格します。以前のプライマリノードが復旧すると、レプリカになり、現在のプライマリノードからデータを複製します。
アップデートやパッチが適用される場合、レプリカはプロアクティブにプライマリにプロモートされ、クライアントは大幅な遅延なしにすぐに再接続できる必要があります。 Basic Tier キャッシュはノードが1つで構成されるため、パッチ適用中に引き継ぐレプリカがないため、アップデートやパッチ適用中に Basic Tier Redis インスタンスはダウンし、パッチ適用プロセスの期間中はアクセスができなくなります。 これが、Basic キャッシュがテスト/開発環境には適しているが、本番環境には推奨されない理由の1つです。
Redisの更新:
Azure Redis サービスには、次の 3 種類の更新プログラムがあります。
- Redis サービスで使用されるバイナリに適用される Redis のアップデート/パッチ。
- 各 Redis ノード VM に対して適用される ホスト のアップデート/パッチ。ホストが更新されるとVMが再起動します。
- 各 Redis ノードVMで使用されるオペレーティングシステムに対して適用されるOSの更新/パッチ。OS の更新後、VMが再起動します。
Azure Redis が Standard または Premium Tier にある場合、Redis のアップデート/パッチ、ホストまたは OS の更新は、Redis の可用性に影響を与えないはずです。
フェイルオーバー:
Redis アップデート/パッチが発生するたびに、Redisフェイルオーバーが開始されます。
フェイルオーバーが発生すると、プライマリノードの現在の接続が切断され、クライアントアプリケーション側でタイムアウトになります。これは想定されることです。
クライアントアプリケーションに表示されるエラーの数は、フェイルオーバー時にその接続で保留されていた操作の数によって異なります。 接続を閉じたノードを介してルーティングされた接続には、エラーが表示されます。 多くのクライアントライブラリは、タイムアウト例外、接続例外、ソケット例外など、接続が切断されたときに様々な種類のエラーをスローする可能性があります。
すべてのプロセスは、このドキュメントで説明されています。フェールオーバーはクライアント アプリケーションにどのような影響を与えますか?
クライアント側からサーバーの更新またはパッチを確認する方法:
現在クライアント側または Azure Portal で Redis、ホスト、またはホスト OS の更新/パッチを確認する方法はありません。これは現在ロードマップにあるものです。
サーバーの更新またはパッチを軽減する方法:
Microsoftのベストプラクティスに従って、アプリケーションは再接続を再試行する必要があり、再試行をおこなうことで、サービスやエンドユーザーに影響を与えることなく新しいプライマリノードに再接続することができます。
Stackexchange.Redis:
Stackexchange.Redis には、デフォルトで再試行ポリシーが設定されています。これにより、クライアント側でタイムアウトが発生する場合がありますが、クライアントの再試行ポリシーによって Redis サービスが常時利用できるはずです。
StackExchange.Redis クライアントライブラリには、 このような接続エラーの処理方法を制御する AbortConnect という名前の設定があります。この設定のデフォルト値は「True」です。これは、場合によっては自動的に再接続されないことを意味します。Microsoft の推奨事項は、AbortConnect を「false」に設定して、ConnectionMultiplexer が自動的に再接続できるようにすることです。
Redis アップデートのスケジュール:
現在 Redis のアップデートをスケジュールできる機能があります。ただし、より頻繁に発生するプラットフォームの更新(ホストまたは OS の更新)については説明していません。そのため、現時点では、すべての種類のアップデートの更新時間を指定することはできません。
更新をスケジュールする方法を示すこのドキュメントを参照してください。更新のスケジュール
2. 実行時間の長いコマンド
一部のコマンドは、その複雑さに応じて、他のコマンドよりも実行にコストがかかります。
Redis はシングルスレッドのサーバーサイドシステムであるため、サーバーがこれらのコストの高いコマンドの処理でビジー状態になる可能性があり、時間のかかるコマンドの実行に時間がかかると、クライアント側で遅延やタイムアウトが発生する可能性があります。
Redis.io のドキュメントに基づくと、Redis.io ページの各コマンドの説明の上部に記載されているように、時間計算量が多い既知のコマンドがいくつかあります。
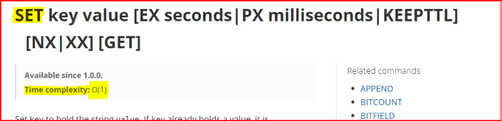
時間計算量:
O(1) - コマンドは 1 つの特定のキーにのみ適用されます。
O(N) - N はデータベース内のキーの数です。これは、コマンドがデータベース内の各キーに適用される(または読み取られる)ことを意味します。これらのコマンドの使用は避けてください。それが不可能な場合は慎重に使用する必要があります。
ここで説明するように、このようなタイプの複雑なコマンドは避ける必要があります。
https://docs.microsoft.com/en-us/azure/azure-cache-for-redis/cache-troubleshoot-server#long-running-commands
また、Redis 側で LUA スクリプトを実行するために使用される Eval コマンドは、完了するまでに時間がかかる場合があります。 Redis コマンドの処理はシングルスレッドであるため、実行に時間がかかるコマンドは、その後に続く他のすべてのコマンドをブロックします。
クライアント側から実行時間の長いコマンドを確認する方法:
Redis-cli コマンドラインコンソールを使用して SlowLog コマンドを実行し、サーバーに対して実行されている高コストなコマンドを測定できます。このコマンドは、Redis の低速クエリログを読み取ったりリセットしたりするために使用され、出力はマイクロ秒単位で表示されます。 SlowLogコマンドの詳細はこちらを参照ください。
また、Azure Portalの「Max CPU」および「Server Load」メトリックを使用して、サーバー側の帯域幅がどれだけ使用されているかを確認できます。これは通常、長時間実行されるコマンドと相互に関連しています。
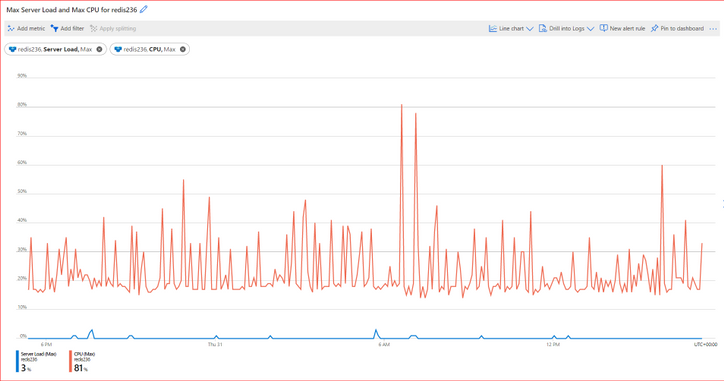
そのためには、チャートで 最大集計 を使用する必要があります。 「Max CPU」および「Server Load」メトリックは、Redis インスタンス毎に、また Redis クラスター化インスタンスの場合はシャード毎に使用できます。その場合、各シャードの「Max CPU」と「Server Load」の使用状況を調査して、特定のシャードの過負荷を特定できるようにする必要があります。
実行中の長時間実行コマンドを軽減する方法:
長時間実行されるコマンドを回避するには、実行コストの高いコマンドを避け、O(1) 計算量のコマンドに置き換える必要があります。
たとえば、 KEYS コマンドは、それが O(N) 操作であることを知らずに使用されることがよくあります。 CPU スパイクを減らすために SCAN O(1) といくつかのリクエストを使用して KEYS を回避することができます。
また、複雑なスクリプトはパフォーマンスへの影響を把握するため、レビューをおこない単純なスクリプトに置き換える必要があります。少量の複雑なスクリプトを保持するよりも、単純なスクリプトを多く保持しておく方が望ましいです。
3. サーバーのCPU高負荷
サーバーの負荷またはCPU使用率が高いということは、サーバーがリクエストを時間内に処理できないことを意味します。サーバーの応答が遅く、リクエストレートに追いついていない可能性があります。 サーバーが期待どおりに応答するのに時間がかかる場合、これはサーバーのパフォーマンスに問題があることを即座に意味するものではありません。Standard およびPremium Redis Tier の Redis サービスには、プライマリおよびレプリカの各 Redis ノードとして Redis サービスの稼働のための専用 VM リソースがあります。 プライマリノードで問題が検出されると、フェイルオーバーが発生し、レプリカノードを新しいプライマリに昇格させて、クライアントアプリケーションから要求されたすべての作業を処理できます。
通常、サーバーが予想よりも応答に時間がかかるのは、クライアントアプリケーションが長時間実行されるコマンドやスクリプトを要求したり、大きなキー値を使用したり、クライアントアプリケーションが要求した全作業を処理するために必要なキャッシュサイズよりも小さい Tier を使用していることが原因です。 また、メモリの負荷が高いとページフォールトが多数発生する可能性があり、ページフォールトが発生するとサーバー側で CPU 使用率が高くなる可能性があります。サーバー側の高いメモリ負荷を調査する方法については、以下のトピック4を参照してください。
クライアント側からサーバーのCPU使用率を確認する方法:
Azure Portalの「CPU」または「Server Load」メトリックを使用して、CPU使用率とサーバー負荷を確認することができます。
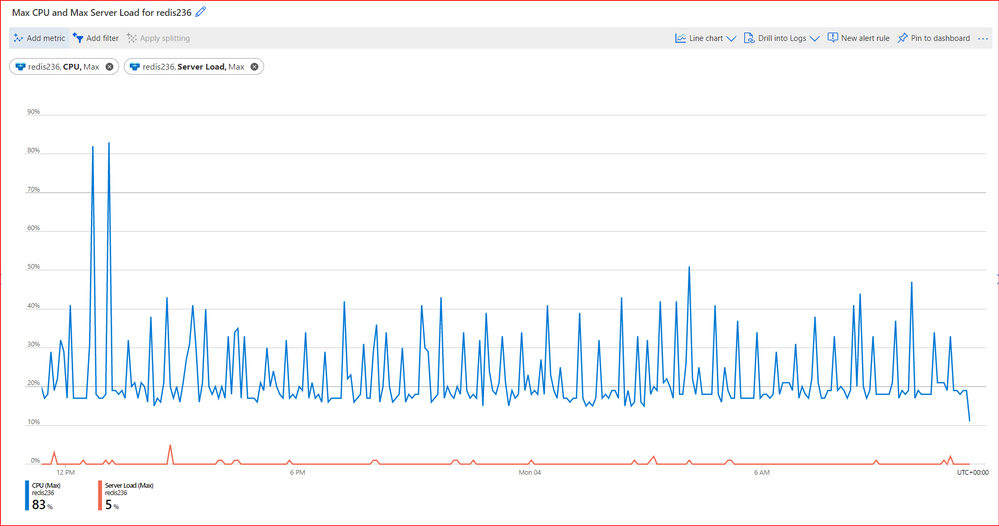
そのためには、チャートで 最大集計 を使用する必要があります。 「CPU」または「Server Load」メトリックは、Redis インスタンス毎に、また Redis クラスター化インスタンスの場合はシャード毎に使用できます。その場合、「CPU」または「Server Load」が高いシャードを特定するために、各シャードを個別に調査する必要があります。
サーバー高CPU使用率を軽減する方法:
サーバーの高負荷を軽減するためにいくつかの実施すべきことがあります。
- 上記のトピック 2 で説明したように使用される長時間実行コマンドを調査します。
- 多くの CPU 容量を持つより大きなキャッシュサイズにスケールさせます。
- CPU や サーバーの負荷などのメトリックに関するアラートを作成して、潜在的な影響について早期に通知します。
4. サーバーの高メモリ負荷
サーバーサイドのメモリ負荷は、リクエスト処理を遅延させるパフォーマンス問題を引き起こす可能性があり、メモリ不足が発生すると、システムはデータをディスクにページングすることがあります。このページフォルトによって、システムの速度が大幅に低下します。
このメモリ不足には、いくつかの原因が考えられます。
- キャッシュが最大容量に近くまでデータで満たされている。
- メモリの断片化が起こっている。Redis は小さなオブジェクト用に最適化されているため、ほとんどの場合、断片化は大きなオブジェクトを格納することによって発生します。
クライアント側からサーバーの高メモリ使用量を確認する方法:
Azure Portal の「used_memory」および「used_memory_rss」メトリックを使用して、使用されているメモリの量を確認できます。
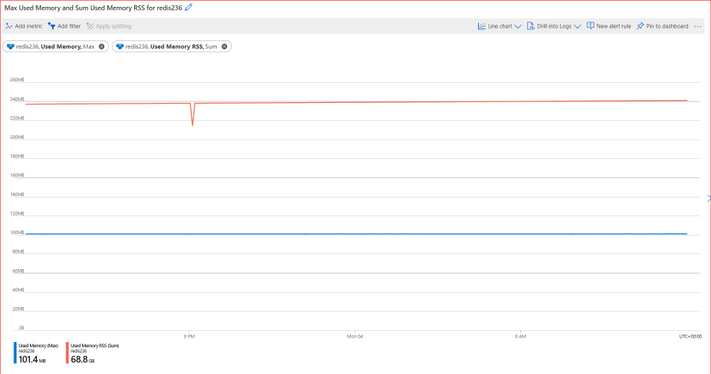
そのためには、チャートで最大集計を使用する必要があります。 -任意の Redis コンソールを使用して Info コマンドを実行できます。このコマンドは、コマンド出力で「Used Memory」および「Used Memory RSS」セクションを探してメモリ使用量を識別するために使用できます。Infoコマンドの使用の詳細を参照してください。
サーバーの高メモリ使用量を軽減する方法:
メモリ使用量を健全に保つために有用なポイントがいくつかあります。
- memory policy を構成し、キーに有効期限を設定します。断片化がある場合、このポリシーでは不十分な場合があります。
- デフォルトの eviction policy は volatile-lru です。これは、使用頻度の低い(LRU:Least Recently Used)キーを最初に削除しようとすることでキーを evict しますが、対象は有効期限が設定されているキーのみです。したがって、 volatile-lru を使用して、キーに有効期限を設定することを強くお勧めします。
- maxmemory-reserved と maxfragmentationmemory-reserved の値を構成します。これは、メモリフラグメンテーションに対処するための十分な大きさを確保する必要があります。Microsoft では、大きなキーサイズを使用する場合、これらの予約値のそれぞれに対してキャッシュのサイズの5%(またはそれ以上)を使用することをお勧めします。上記の点については、メモリポリシーの設定方法をご覧ください。
- クライアントアプリケーションロジックを確認し、大きなキャッシュオブジェクトを小さなオブジェクトに分割します。
- 多くのよりメモリ容量を持つ大きなキャッシュサイズにスケールさせます。
- “used_memory” や “used_memory_rss” などの指標に関するアラートを作成して、潜在的な影響について早期に通知します。
5. Redis サーバーの帯域幅制限の超過
Redis サーバーの帯域幅の制限を超過した場合や、その他のネットワーク起因のタイムアウトについては次の TechCommunity の記事 Azure Redis Timeouts - Network Issues で述べています。
おわりに
クライアント、サーバー、またはネットワーク側でなんらかの問題が発生すると Azure Cache for Redis への接続でタイムアウトが発生する可能性があります。 クライアント、またはネットワーク起因の Redis タイムアウトの原因については、次の TechCommunity の記事を参照してください 。
Azure Redis Timeouts - Client Side Issues
Azure Redis Timeouts - Network Issues
関連ドキュメント
Azure Cache for Redis のタイムアウトのトラブルシューティング Redisコマンド Azure Cache for Redis を監視する方法
-
サーバーサイドのアップデート/パッチ
フェールオーバーはクライアント アプリケーションにどのような影響を与えますか?
更新のスケジュール -
長時間実行されるコマンド
SLOWLOG
実行時間の長いコマンド -
サーバーの高CPU負荷
高い CPU 使用率またはサーバーの負荷 -
サーバーの高メモリ不可
Eviction policies
Memory policies
Redis サーバーでのメモリ不足
INFO コマンド